

지난 5편 — 4 AI 답변 엔진 비교에서는 ChatGPT · Perplexity · Gemini · Claude가 인용하는 페이지가 어떻게 다른지를 정리했어요. 한 가지 짚지 않고 넘어간 게 있어요 — 네 엔진 모두에서 인용 적격성의 1차 관문은 같다는 사실. 바로 우리 페이지가 기계가 읽을 수 있게 구조화되어 있는가입니다.
이게 6편의 출발점이에요. 마케터·콘텐츠 운영자가 Schema.org와 llms.txt라는 단어를 한 번쯤 들어봤어도, 그래서 우리 페이지의 어디에 무엇을 어떻게 붙여야 하는지 막막한 게 보통입니다. 더 어려운 건 — Google이 직접 generative AI 검색에 특별한 schema.org 마크업은 없다고 공식 명시한 상황이라는 거예요 (2026-05-15 갱신). llms.txt에 대해서도 같은 페이지에서 필요 없다고 적습니다. 그러면 Schema·llms.txt는 왜·어떻게 쓸까요?
이 글은 4편의 AI Overview 변화 + 5편의 4 엔진 인용 차이 위에 — Schema.org · llms.txt가 기계가 우리 브랜드를 정확히 읽게 만드는 보조 인프라임을 정직하게 풀고, 오늘 적용할 수 있는 6가지 마크업 패턴을 복사·붙여넣기 가능한 JSON-LD 코드와 함께 정리합니다. 변호사·세무사·노무사 같은 전문직 사무소를 위한 vertical 패턴도 함께 짚어요 — 다만 Attorney 타입이 schema.org에서 deprecated된 사실 같은 잘못 알려진 부분도 같이 바로잡습니다.
출처는 Schema.org 공식 (v30.0), Google Search Central 두 문서(Intro to structured data + AI optimization guide), llmstxt.org 원본 제안, SISTRIX TOP 100 AI 인용 분석, ACL/EMNLP 2025 학술, 그리고 실제 라이브 변호사·회계 사이트 사례까지 묶었습니다. 검증된 1차 자료만 사용했어요.
Schema.org가 뭐고, AI 답변 엔진에 왜 중요한가요?
Schema.org는 웹 페이지의 의미 구조를 기계가 읽을 수 있도록 표준화한 공통 어휘예요. 2011년 Google·Bing·Yahoo·Yandex가 공동으로 만든 표준이고, 2024년 기준 4,500만 개가 넘는 도메인이 4,500억 개 이상의 객체로 페이지를 마크업하고 있어요. AI 답변 엔진이 등장하기 한참 전에 만들어진 어휘인데, 지금 다시 주목받는 이유는 단순해요 — AI가 페이지를 읽을 때 회사명·주소·서비스·FAQ·저자가 무엇인지 단번에 알게 해주는 구조가 바로 Schema거든요.
Schema.org 공식 홈페이지는 자신을 이렇게 정의해요. “Schema.org is a collaborative, community activity with a mission to create, maintain, and promote schemas for structured data on the Internet.” — 인터넷상의 구조화 데이터를 위한 스키마를 만들고 유지·보급하는 공동 활동이에요. 같은 페이지 하단에 채택 규모도 그대로 적혀 있어요. “As of 2024, over 45 million web domains markup their web pages with over 450 billion Schema.org objects.”

Schema.org는 세 가지 syntax(문법)를 지원해요. JSON-LD · Microdata · RDFa 세 가지인데, 실무에서는 거의 JSON-LD 한 가지로 수렴했어요. Google Search Central — Introduction to structured data markup 문서가 그 이유를 직접 짚어요. “JSON-LD is easiest to implement, maintain, and recover from errors.” — 구현·유지·오류 복구가 가장 쉽다는 이유로 Google이 공식 권장하는 형식이에요.
JSON-LD (권장): <head> 또는 본문에 <script type="application/ld+json"> 블록으로 삽입. 콘텐츠와 마크업이 분리되어 유지·보수가 가장 쉬워요. Google·Bing 모두 1순위.
Microdata: HTML 태그 안에 itemscope·itemtype 속성을 직접 추가. 마크업이 콘텐츠와 섞여서 관리가 번거로워요.
RDFa: HTML 태그 안에 vocab·typeof 속성. 학술·문서형 사이트에 가끔 보이지만 SEO 실무에서는 거의 사용 X.
여기서 가장 정직하게 짚을 부분이 있어요 — Google은 생성형 AI 검색에 특별한 schema.org 마크업이 필요하지 않다고 공식 명시했어요. Google Search Central — Optimizing your website for generative AI features on Google Search 문서의 Mythbusting → Overfocusing on structured data 섹션이 그 출처예요 (2026-05-15 갱신). “Structured data isn’t required for generative AI search, and there’s no special schema.org markup you need to add.” — 구조화 데이터는 생성형 AI 검색에 필수가 아니며, 추가해야 하는 특별한 schema.org 마크업도 없다는 직접 표현입니다.
즉, “Schema를 붙이면 AI Overview·AI Mode에서 자동으로 더 잘 인용된다” 같은 단정은 공식 문서 기준으로 과장이에요. 그러면 왜 쓸까요?
답은 SISTRIX의 The Path to AI Citations — TOP 100 분석 (2025-12-04)에 있어요. Google AI Mode에서 가장 많이 인용된 상위 100개 사이트를 분석했더니, 두 가지 공통점이 도드라졌어요. Pillar 2 — authority + recency(권위·최신성), 그리고 그 신호를 JSON-LD로 표현한 것. Pillar 3 — strict machine readability(엄격한 기계 가독성). 즉 AI에 인용되는 페이지의 절대다수가 JSON-LD를 쓰고 있고, 페이지 자체가 기계가 읽기 쉬운 구조로 짜여 있다는 관찰이에요. SISTRIX의 표현이 가장 직접적입니다. “Web pages that are cited by AIs are not linear texts, they are databases of responses.” — AI에 인용되는 웹페이지는 선형 텍스트가 아니라 응답 데이터베이스다.
검색 성과 쪽에서는 더 정량적인 사례도 있어요. Google Search Central의 Rakuten Recipe 케이스 스터디 (2018-05-08, 라이브)는 Recipe Schema를 적용한 결과 검색 유입이 2.7배로 급증했고 평균 세션 지속시간이 1.5배 길어졌다고 보고합니다. “Traffic to all Rakuten Recipe pages from search engines soared 2.7 times, and the average session duration was now 1.5 times longer than before.” — 다만 이건 검색 성과지 AI 인용 효과가 아니에요. 두 가지는 분리해서 봐야 정직합니다.
Schema.org가 마케터에게 어떻게 보이는지 한 번 짧게 보시면 이해가 더 빨라요. Google Search Central의 Martin Splitt이 Structured Data for beginners에서 _구조화 데이터가 왜·어떻게 작동하는지_를 짧게 풀어줍니다.
Schema 없는 페이지 vs Schema 있는 페이지
같은 변호사 사무소 페이지를 AI가 어떻게 다르게 읽는가
출처: SISTRIX TOP 100 분석 (2025-12-04) · Schema.org LegalService
정리하면 이래요. Schema.org는 AI 인용의 전용 패스권이 아니에요 — Google이 직접 그렇게 말합니다. 하지만 인용 적격성의 1차 관문이긴 해요. 기계가 우리 페이지를 정확히 읽을 수 있어야 비로소 AI 답변 엔진의 평가권에 들어가요. SISTRIX TOP 100이 보여준 게 바로 이 지점이에요 — AI에 인용되는 페이지의 공통 인프라가 Schema라는 관찰. 이게 우리가 6편에서 Schema를 다루는 이유예요.
📌 Schema.org는 4,500만 도메인이 채택한 기계가 읽을 수 있는 공통 어휘. Google이 AI 검색에 필요 없다고 말해도, AI에 인용되는 100대 사이트의 공통점이 JSON-LD라는 SISTRIX 관찰이 그 보조 인프라 가치를 증명해요. 전용 패스권은 아니지만 인용 적격성의 1차 관문입니다.
llms.txt가 뭐고, AI 크롤러가 어떻게 읽나요?
llms.txt는 AI 크롤러에게 우리 브랜드를 짧게 요약해 안내하는, 사이트 루트에 두는 마크다운 파일이에요. 2024년 9월 3일 Jeremy Howard(answer.ai 창업자)가 llmstxt.org에서 처음 제안했고, 표준이 아니라 제안(proposal)이라는 점이 원문 첫 문장에 명시돼 있어요. “A proposal to standardise on using an /llms.txt file to provide information to help LLMs use a website at inference time.” — 추론 시점에 LLM이 웹사이트를 활용하도록 돕는 정보를 제공하기 위해 /llms.txt 파일 사용을 표준화하자는 제안입니다.
robots.txt·sitemap.xml과는 역할이 분명히 달라요. robots.txt는 크롤러의 접근을 허용·차단하는 게이트이고, sitemap.xml은 크롤러가 발견해야 할 URL 목록입니다. llms.txt는 그 위에 우리 브랜드를 짧게 요약하면 이렇다 / 핵심 페이지는 이것들이다 / 자체 용어는 이렇게 정의한다는 마케팅 컨텍스트를 얹어주는 레이어예요.
robots.txt · sitemap.xml · llms.txt 역할 비교
세 파일은 같은 크롤러를 대상으로 하지만 역할이 분명히 다르다
역할: 크롤러 접근 허용·차단.
제어 단위: user-agent + URL 패턴.
OpenAI·Anthropic·Perplexity 공식: 모두 robots.txt를 1차 제어면으로 명시.
역할: 크롤러가 발견해야 할 URL 목록 안내.
제어 단위: URL + lastmod + priority.
실효: Google·Bing 모두 정식 표준으로 수용.
역할: AI 크롤러에게 브랜드 요약·핵심 페이지·자체 용어 안내.
제어 단위: 마크다운 문서 한 파일.
실효: 도입 권고 수준 — 공식 표준 X, Google "필요 없음" 명시.
출처: llmstxt.org 원본 제안 (2024-09-03) · Google AI optimization guide (2026-05-15)
채택은 빠르게 늘고 있어요. Anthropic(docs.anthropic.com/llms.txt), Perplexity(자체 인덱스), Vercel(llms.txt + llms-full.txt 패턴) 같은 AI·개발자 도구 회사들이 먼저 도입했어요. Vercel은 Add llms.txt 공식 가이드에서 “Vercel uses this pattern for their own docs.” 라고 직접 적습니다.
여기서 가장 정직하게 짚을 부분이 있어요. OpenAI · Anthropic · Perplexity 그 어느 공식 문서에도 제3자 사이트의 llms.txt를 답변 생성에 활용한다는 명시는 없습니다. 세 회사 모두 robots.txt + user-agent 제어를 공식 메커니즘으로 설명해요.
| 회사 | 공식 봇 구분 | 1차 제어면 | 제3자 llms.txt 활용 명시 |
|---|---|---|---|
| OpenAI (공식) | OAI-SearchBot · GPTBot · ChatGPT-User |
robots.txt + user-agent | ❌ 없음 |
| Anthropic (공식) | ClaudeBot · Claude-User · Claude-SearchBot |
robots.txt + user-agent | ❌ 없음 |
| Perplexity (공식) | PerplexityBot · Perplexity-User |
robots.txt + user-agent + WAF | ❌ 없음 (자체 docs에는 인덱스 운영) |
더 직접적인 한계 표시도 있어요. 앞에서 인용한 Google “AI optimization guide”는 Schema뿐 아니라 llms.txt에 대해서도 필요 없다고 공식 명시해요. “LLMS.txt files and other ‘special’ markup: You don’t need to create new machine readable files, AI text files, markup, or Markdown to appear in generative AI search.” — 생성형 AI 검색에 표시되기 위해 새로운 기계 읽기 파일이나 AI 텍스트 파일을 만들 필요는 없다는 게 Google의 입장입니다.
그러면 왜 도입할까요? 세 가지 이유가 있어요.
1. 도입 비용이 매우 낮습니다. 마크다운 한 파일. 한 시간이면 작성 가능해요.
2. 채택 트렌드가 빠릅니다. Anthropic·Perplexity·Vercel 같은 AI·인프라 회사가 먼저 표준화에 참여 중이고, 비공식 로그 분석에서는 OpenAI 봇이 실제로 /llms.txt 경로를 크롤링한다는 관찰이 보고됩니다.
3. Perplexity는 자기 자신의 llms.txt 인덱스를 운영합니다. 문서 사이트 안내에 공식 활용 중이에요. 제3자 사이트의 llms.txt를 어떻게 활용하느냐는 명시가 없을 뿐이에요.
즉 llms.txt는 공식 표준이자 검증된 효과 도구가 아니라 도입 권고 수준의 보조 인덱스로 이해하는 게 정직해요. GeoMoment도 같은 입장에서 자체 사이트에 라이브 운영 중이고, 작성 방법은 H2-5에서 풀게요.
📌 llms.txt는 도입 권고 수준의 보조 인덱스예요. Google·OpenAI·Anthropic·Perplexity 공식 문서에 제3자 llms.txt 활용 명시는 없지만, 도입 비용 1시간·채택 트렌드·Perplexity 자체 인덱스 운영을 고려하면 지금 적용이 합리적 선택입니다.
우리 브랜드에 꼭 적용해야 할 Schema 타입은?
모든 브랜드는 3가지 공통 Schema로 시작하면 됩니다 — Organization · Article(블로그용) · FAQPage. 여기에 산업별로 1~2개를 더하면 AI가 우리 브랜드의 정체·콘텐츠·답변을 정확히 인식할 수 있어요. 산업별 매핑은 아래 표와 같아요.
| 산업 | 필수 추가 Schema | 비고 |
|---|---|---|
| 변호사·로펌 | LegalService (사무소) + Person + hasCredential (개별 변호사) |
⚠️ Attorney 타입은 schema.org에서 deprecated — LegalService가 더 포괄적이고 덜 모호함이 공식 권고 |
| 세무·회계·노무 | AccountingService (사무소) + Person + hasCredential (개별 전문가) |
회계는 FinancialService 계열, 세무는 AccountingService 통합 |
| 커머스·이커머스 | Product + Offer + BreadcrumbList |
Rich Results 효과가 가장 큰 영역 |
| 로컬 사업 (식당·매장·병원) | LocalBusiness + Place + openingHoursSpecification |
NAP(이름·주소·전화) 일관성 필수 |
⚠️ Attorney 타입의 deprecated 처리는 본문에서 한 번 더 짚을 가치가 있어요. 외부 SEO 자료 중엔 여전히 개별 변호사 페이지를 Attorney로 마크업하라고 안내하는 글이 많은데, schema.org 공식 페이지는 정확히 이렇게 적습니다. “This type is deprecated - LegalService is more inclusive and less ambiguous.” 따라서 법인·사무소는 LegalService, 개별 변호사 프로필은 Person + hasCredential · alumniOf · award · knowsAbout 조합이 현재 공식 정합 패턴이에요.
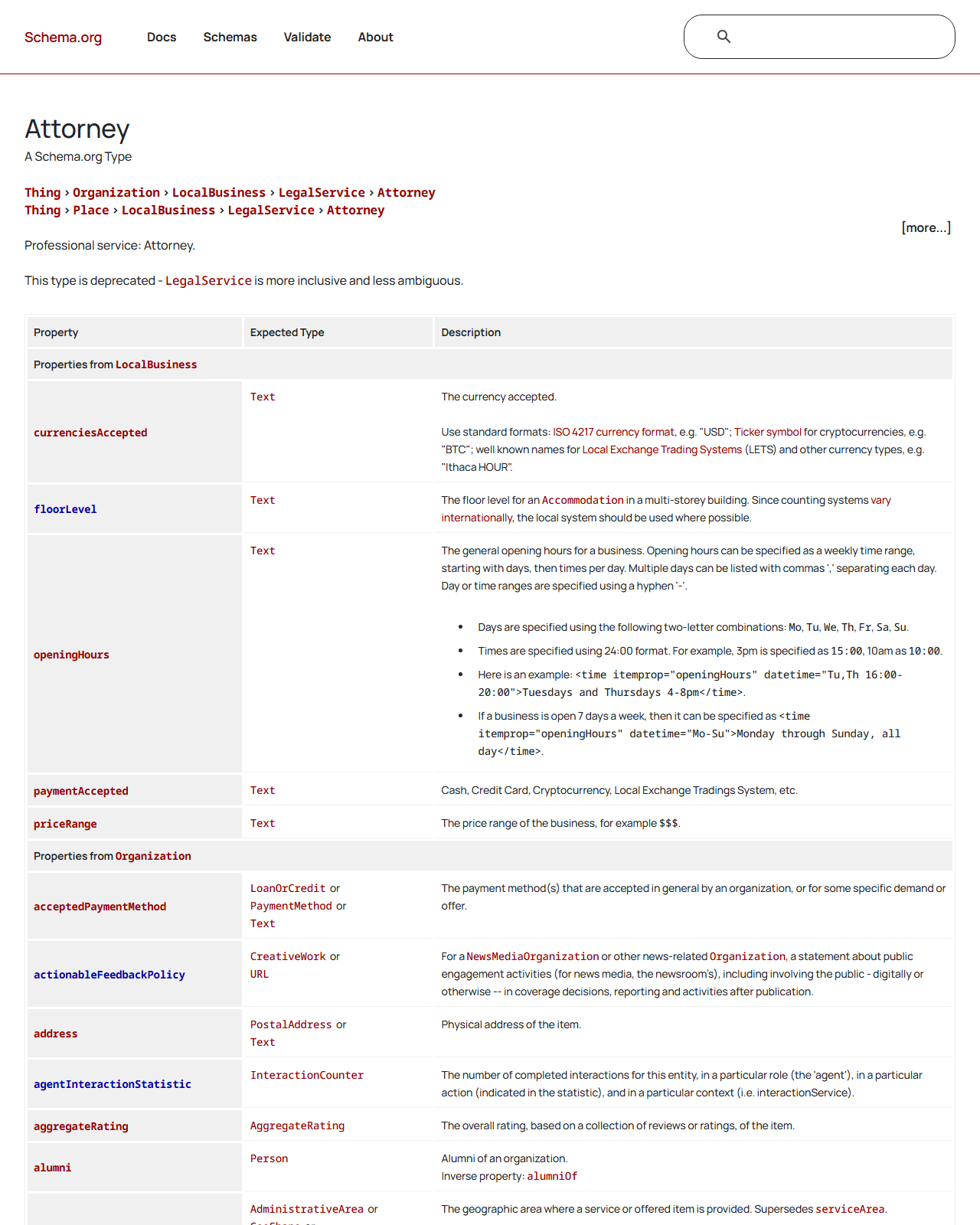
/Attorney 공식 페이지 — "This type is deprecated — LegalService is more inclusive and less ambiguous"가 페이지 상단 부제에 그대로 표시됩니다. 변호사 vertical 자료에서 가장 자주 잘못 알려지는 부분이 이 deprecated 처리예요.실제 라이브 사례도 짚어볼게요. Dynamis LLP의 Government & Internal Investigations 페이지는 상단 JSON-LD에 @type: LegalService와 serviceType·areaServed·provider를 분리해서 기술해요 — “이 페이지는 무슨 서비스 / 어디 지역 / 누가 제공하는가”를 한 번에 구조화한 패턴이에요. 회계 쪽도 마찬가지예요. United Accounting의 NJ Paramus 페이지는 @type: AccountingService에 telephone·address·openingHoursSpecification·aggregateRating까지 한 번에 넣어요. 서비스 타입 + 신뢰 신호 + 로컬 실체성이 한 페이지에 결합된 vertical 표준 패턴입니다.
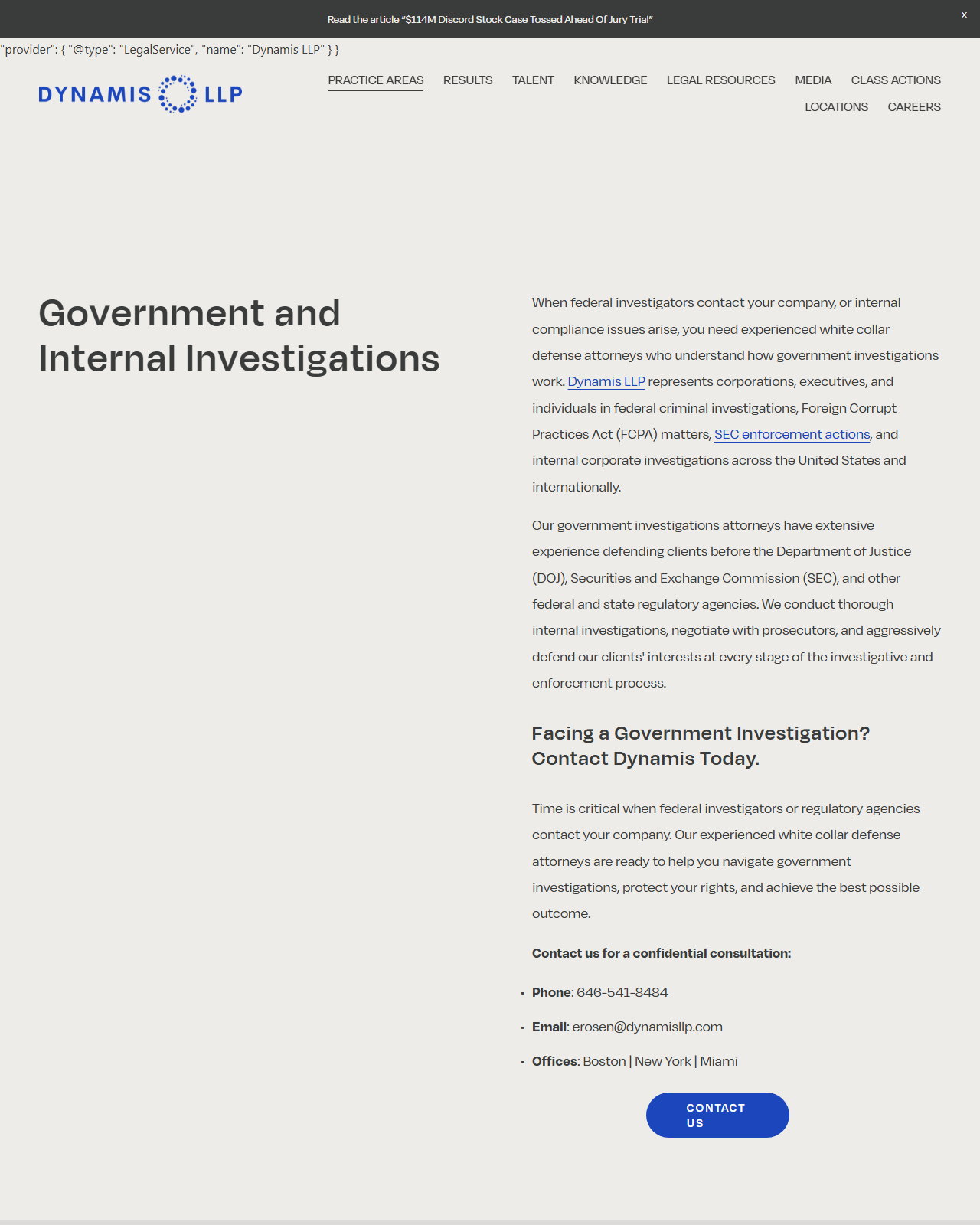
@type: LegalService와 serviceType·areaServed·provider를 분리해 기술한 실전 vertical 사례입니다.산업별 Schema 타입 매트릭스
공통 3종 + 산업별 1~2종 — 우리 브랜드는 어디에 속하나
출처: Schema.org v30.0 · Dynamis LLP (LegalService 실전) · United Accounting (AccountingService 실전)
📌 공통 3종(Organization·Article·FAQPage) + 산업별 1~2종으로 시작. 변호사는 LegalService + Person + hasCredential 조합이 공식 정합 — Attorney 타입은 deprecated라는 점이 자료별로 가장 자주 잘못 알려진 부분입니다.
마크업을 어디에 어떻게 적용하나요? — 실제 코드 패턴 5종
아래 5가지 JSON-LD 코드를 그대로 복사해서 플레이스홀더만 우리 브랜드 정보로 교체하면 오늘 적용 가능합니다. 모두 <head> 또는 본문 끝의 <script type="application/ld+json"> 블록에 넣고, 적용 후에는 Rich Results Test(구조화 데이터가 올바른지 1분 만에 확인해주는 Google 공식 검증 도구)에서 검증할 수 있어요.
1. 사이트 HTML의 <head> 영역을 찾거나(권장) 본문 끝에 위치를 잡아요.
2. 아래 5가지 코드 중 우리 브랜드에 해당하는 패턴의 <script type="application/ld+json"> 블록을 통째로 붙여넣어요.
3. "브랜드명"·"https://example.com"·"02-XXXX-XXXX" 같은 플레이스홀더만 우리 정보로 교체합니다.
4. Rich Results Test에 페이지 URL이나 JSON 코드를 직접 입력해서 오류·경고 0개를 확인하면 끝.
코드 5종에 들어가기 전에 Google Search Central의 John Mueller가 짧게 풀어준 JSON-LD를 페이지의 어디에 넣어야 하는지 영상도 같이 보시면 위치 감이 빠르게 잡혀요.
패턴 1 — Organization (사이트 전체)
회사·브랜드 정체성을 사이트 전 페이지에서 동일하게 선언하는 마크업이에요. 보통 <head> 안에 넣고, 모든 페이지 공통으로 출력합니다.
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "브랜드명",
"url": "https://example.com",
"logo": "https://example.com/logo.png",
"sameAs": [
"https://www.facebook.com/your-page",
"https://www.instagram.com/your-handle",
"https://www.linkedin.com/company/your-company"
],
"contactPoint": {
"@type": "ContactPoint",
"telephone": "+82-10-XXXX-XXXX",
"contactType": "customer service",
"areaServed": "KR",
"availableLanguage": ["Korean", "English"]
}
}
패턴 2 — BlogPosting (블로그 글마다)
블로그 글 페이지마다 1개씩. 저자·발행일·수정일·이미지를 구조적으로 명시해서, AI가 누가·언제·무엇을 정확히 파악할 수 있게 해요. SISTRIX TOP 100 분석의 Pillar 2 (authority + recency)가 바로 이 영역이에요.
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"headline": "글 제목",
"image": "https://example.com/og-image.png",
"datePublished": "2026-05-19T10:00:00+09:00",
"dateModified": "2026-05-19T15:00:00+09:00",
"author": {
"@type": "Person",
"name": "저자 이름",
"url": "https://example.com/authors/jace"
},
"publisher": {
"@type": "Organization",
"name": "브랜드명",
"logo": {
"@type": "ImageObject",
"url": "https://example.com/logo.png"
}
}
}
패턴 3 — FAQPage (FAQ 또는 Q&A H2 패턴)
Q&A 형식의 콘텐츠를 그대로 구조화. 시리즈 표준 Q&A H2 패턴이 곧 FAQPage가 돼요. AI 답변 엔진은 FAQPage를 직접 응답 후보로 인식하기 쉬워요.
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [
{
"@type": "Question",
"name": "Schema.org가 뭐고 왜 중요한가요?",
"acceptedAnswer": {
"@type": "Answer",
"text": "Schema.org는 웹 페이지의 의미 구조를 기계가 읽을 수 있도록 표준화한 공통 어휘로, 2024년 기준 4,500만 도메인이 채택한 공동 표준입니다."
}
},
{
"@type": "Question",
"name": "llms.txt가 뭐고 어떻게 작성하나요?",
"acceptedAnswer": {
"@type": "Answer",
"text": "llms.txt는 사이트 루트에 두는 마크다운 파일로, AI 크롤러에게 브랜드를 짧게 요약 안내하는 역할을 합니다. 2024년 9월 Jeremy Howard가 제안했습니다."
}
}
]
}
패턴 4 — LegalService 또는 AccountingService (전문직 사무소)
변호사·회계·세무·노무 사무소의 서비스 페이지·홈페이지에 적용. LocalBusiness 상속 속성(openingHours·address·telephone)도 함께 넣어요.
{
"@context": "https://schema.org",
"@type": "LegalService",
"name": "○○ 법무법인",
"url": "https://example-law.com",
"telephone": "+82-2-XXXX-XXXX",
"address": {
"@type": "PostalAddress",
"streetAddress": "서울 강남구 ○○로 ○○",
"addressLocality": "서울",
"postalCode": "06XXX",
"addressCountry": "KR"
},
"openingHoursSpecification": [{
"@type": "OpeningHoursSpecification",
"dayOfWeek": ["Monday", "Tuesday", "Wednesday", "Thursday", "Friday"],
"opens": "09:00",
"closes": "18:00"
}],
"serviceType": ["이혼 소송", "상속 분쟁", "기업 자문"],
"areaServed": {"@type": "Place", "name": "대한민국"},
"priceRange": "₩₩₩"
}
세무·회계·노무 사무소는 @type만 AccountingService로 바꾸면 같은 골격이 그대로 적용돼요. serviceType을 세무 신고·법인 결산·노무 자문 등 사무소 특성으로 교체하시면 끝.
패턴 5 — Person + hasCredential (저자·전문가·변호사)
저자·변호사·세무사·회계사 개별 프로필 페이지. EEAT(Experience · Expertise · Authoritativeness · Trustworthiness — Google이 콘텐츠 신뢰도를 판단하는 4가지 기준) 신호의 핵심이에요. 학력·자격·수상·전문 분야를 모두 구조화합니다. (⚠️ Attorney 타입이 deprecated 처리됐기 때문에 변호사 개인 프로필도 Person을 사용해요.)
{
"@context": "https://schema.org",
"@type": "Person",
"name": "홍길동",
"jobTitle": "대표 변호사",
"url": "https://example-law.com/attorneys/hong",
"image": "https://example-law.com/hong.jpg",
"worksFor": {
"@type": "LegalService",
"name": "○○ 법무법인"
},
"alumniOf": [
{"@type": "EducationalOrganization", "name": "서울대학교 법학과"},
{"@type": "EducationalOrganization", "name": "사법연수원 제○○기"}
],
"hasCredential": [
{
"@type": "EducationalOccupationalCredential",
"credentialCategory": "license",
"name": "대한민국 변호사"
}
],
"knowsAbout": ["이혼 소송", "양육권 분쟁", "재산분할"],
"award": ["○○ 법조타임스 올해의 변호사 (2025)"]
}
5종 모두 Rich Results Test에서 구문 검증 + Google 인식 가능성을 1분 만에 확인할 수 있어요. 운영 시점에는 Google “Intro to structured data” 문서의 권고처럼 Search Console의 Rich result status reports로 마크업 깨짐 여부를 모니터링하면 안전합니다.
📌 5종 JSON-LD 코드를 그대로 복사해서 플레이스홀더만 교체하면 오늘 적용 가능. Organization·BlogPosting·FAQPage는 모든 브랜드 공통, LegalService/AccountingService·Person+hasCredential은 전문직 사무소 vertical 직격 패턴입니다.
llms.txt 작성 — 무엇을 적고 무엇을 빼야 하나요?
llms.txt는 회사 자랑이 아니라 AI가 우리 브랜드를 정확히 요약·안내할 수 있게 만드는 메타데이터 파일이에요. llmstxt.org가 제안한 표준 구조는 제목 → TLDR → 핵심 페이지 → 자체 용어 → FAQ 5요소이고, 이게 GeoMoment 라이브 llms.txt에 그대로 적용된 모습이에요.
여기서 흥미로운 부수 발견 하나 — 미국 변호사 업계에선 AI에 인용되는 변호사 vs AI 인용으로 징계받는 변호사라는 대비가 만들어지고 있어요. 우리가 본문에서 짚는 AI에 출처로 인용되는 사이트 만들기의 반대편에서, AI가 만든 가짜 판례를 그대로 인용했다가 법원 징계를 받은 변호사 사례가 다수 보고되고 있거든요. 우리 브랜드가 전자가 되려면 llms.txt와 Schema가 기계가 정확히 읽을 정직한 사실을 정리해주는 자료 역할을 해야 해요.
라이브 GeoMoment llms.txt에서 핵심 구조 5요소를 발췌하면 이래요.

llms.txt — 제목·TLDR·핵심 페이지·자체 용어·FAQ 5요소를 그대로 보여줍니다. 이 글이 발행되는 시점에 6편도 블로그 핵심 콘텐츠로 등록됩니다.# GeoMoment
> 한국 브랜드를 ChatGPT·Gemini·Perplexity·Claude 답변과 네이버 검색 1페이지에 동시에 등장시키는 통합 마케팅 파트너. AI 검색 최적화(GEO)와 브랜드 블로그(SEO) 두 가지 서비스를 한 회사에서 책임집니다.
## 핵심 서비스
- **AI 검색 최적화 (GEO)** — ChatGPT·Gemini·Perplexity·Claude 4개 AI 답변 엔진에서 브랜드 가시성 측정·분석·개선
- **브랜드 블로그 (SEO)** — 네이버·구글 검색 결과 1페이지 노출
## 주요 페이지
- [GEO 서비스](https://geomoment.me/geo.html)
- [무료 GEO 진단](https://geomoment.me/geo-diagnose.html)
- ...
## 자체 용어 사전
- **GEO**: 생성형 엔진 최적화 ...
- **4 AI**: ChatGPT · Gemini · Claude · Perplexity ...
## 자주 묻는 질문
### Q. AEO와 SEO의 차이는?
A. SEO는 ... AEO는 ...
5요소만 갖춰도 AI가 우리 브랜드의 정체·서비스·핵심 페이지·전문 용어·자주 묻는 질문을 한 파일에서 다 인식할 수 있어요. 반대로 잘못 쓰는 패턴 3가지도 짚어둘게요.
1. 회사 자랑만 길게. 업계 최고, 혁신적인, 차별화된 같은 마케팅 수식어는 AI가 가중치 두지 않아요. 정량적 사실(연차·고객 수·특허 출원 번호·연락처)을 적으세요.
2. TLDR 없이 긴 문서. llms.txt는 짧은 안내가 핵심이에요. 본문이 길면 AI가 요점을 못 잡고, 차라리 llms-full.txt(상세본)를 별도로 두는 Vercel 패턴을 추천합니다.
3. 의미 없는 메타데이터. HTML 메타 태그를 그대로 옮긴 키워드 나열은 현대 LLM에 거의 효과 없음. 사람이 읽을 자연스러운 한국어 문장으로 쓰세요.
llms.txt — 잘못 쓴 예 vs 잘 쓴 예
같은 회사의 llms.txt를 두 가지 방식으로 작성하면 AI 인식이 어떻게 달라지나
문제: 정량 사실 없음 · TLDR 없음 · 의미 없는 키워드 나열. AI 시야: 무엇을 하는 회사인지 추출 불가.
장점: TLDR 1줄로 정체 즉시 전달 · 정량 사실(5,000+ 키워드) · 핵심 페이지 직접 링크. AI 시야: 회사 정체·서비스·핵심 페이지를 한 번에 인식.
📌 llms.txt 5요소(제목·TLDR·핵심 페이지·자체 용어·FAQ)만 갖추면 충분. 회사 자랑 대신 정량적 사실, 긴 문서 대신 TLDR + llms-full.txt 분리, 키워드 나열 대신 자연스러운 한국어 문장이 핵심이에요.
Schema · llms.txt 점검·유지 — 30분 체크리스트
Schema·llms.txt는 한 번 붙이고 끝이 아니라 배포 파이프라인과 동기화한 자동 재생성이 운영 핵심이에요. 분기별 같은 고정 주기 갱신은 어느 공식 문서에도 명시되어 있지 않아요. 대신 템플릿·서비스·문서 IA가 바뀌는 시점에 함께 재생성되도록 빌드 파이프라인에 끼워두는 게 가장 안전합니다.
발행 또는 갱신 시점에 30분이면 끝나는 5단계 체크리스트는 이렇게 짜요.
1. Schema 구문 검증 — Rich Results Test에서 페이지 URL 또는 JSON 코드 직접 입력. 오류·경고 0개 확인.
2. llms.txt 접근 확인 — https://your-site.com/llms.txt 직접 브라우저에서 열기. 200 OK 응답 + 마크다운 렌더링 확인.
3. 모바일 노출 확인 — Schema가 데스크톱만이 아니라 모바일 페이지에도 동일하게 출력되는지 모바일 source 확인.
4. Rich result status reports — Search Console에서 구조화 데이터 섹션 확인. 신규 오류·경고 발생 여부 모니터링.
5. 배포 파이프라인 동기화 — 사이트 템플릿·서비스 변경·문서 IA 개편 시 Schema·llms.txt가 자동 재생성되도록 빌드 스크립트에 포함.
6편에서 짚은 구조화 데이터 가독성이 우리 브랜드 페이지에 실제로 얼마나 갖춰져 있는지 궁금하시면 GeoMoment 무료 진단으로 ChatGPT·Gemini·Perplexity·Claude 4개 AI 답변 엔진에서의 인용 적격성을 측정해 보실 수 있어요. Schema 적용 약점과 청크 단위 처방 카드도 1페이지 PDF로 함께 발송해 드립니다.
📌 분기별 갱신은 공식 권고가 없어요. 배포 파이프라인 동기화가 운영 핵심. 30분 점검 5단계(Rich Results Test · llms.txt 200 OK · 모바일 source · Search Console · 빌드 스크립트)면 충분히 안정 운영 가능합니다.