

블로그 한 편을 두 시간 들여 잘 썼는데 ChatGPT가 우리 페이지 대신 다른 회사 페이지를 인용해 본 적 있으세요? 저도 처음엔 ‘SEO도 잘 됐는데 왜?’ 라고 생각했어요. 답은 페이지가 아니라 청크에 있었습니다.
AI는 페이지 전체를 통째로 읽지 않아요. 페이지를 200~500 토큰의 작은 덩어리(=청크)로 자른 뒤, 사용자 질문과 가장 잘 맞는 청크 한 개를 골라 답변의 근거로 씁니다. 같은 페이지 안에서도 어떤 청크는 뽑히고, 어떤 청크는 묻혀요.
이 글에서는 라이터가 오늘부터 페이지를 다시 쓸 수 있는 5가지 청크 처방 패턴을 정리합니다. Anthropic·LlamaIndex·EMNLP 학술 출처로 왜 효과가 있는지 짚고, 한국어 콘텐츠에 어떻게 옮길지까지 다뤄볼게요.
청크가 뭐고 AI는 왜 청크 단위로 인용하나요?
청크는 200~500 토큰 정도의 의미 단위 문단이고, AI는 답변을 만들 때 페이지 전체가 아니라 이 청크 하나를 골라 인용해요. 그래서 좋은 페이지를 쓰는 것보다 좋은 청크를 쓰는 게 GEO의 본질에 가깝습니다.
용어가 낯설 수 있어서 한 번 짚을게요. “토큰” 은 AI가 글을 이해할 때 쓰는 단위인데, 한국어 기준으로 1 토큰 ≈ 한글 1~1.5자예요. 200~500 토큰은 대략 한글 300~750자, 즉 한 문단~짧은 한 절 분량입니다. 지금 보고 계신 이 문단 정도가 청크 1개라고 보시면 됩니다.
조금 더 풀어볼게요. ChatGPT나 Perplexity 같은 AI가 답변을 만드는 방식은 대략 이래요. 사용자 질문이 들어오면, 인덱스에 저장된 웹페이지를 작은 덩어리(=청크)로 잘라 놓고, 그중 질문과 가장 가까운 청크 몇 개를 골라 답변의 근거로 씁니다. 이걸 RAG(Retrieval-Augmented Generation) 패턴이라고 부르는데, 오늘날 거의 모든 생성형 검색이 비슷한 구조로 돌아가요.
사용자가 ChatGPT에 "브랜드 블로그 잘 운영하는 한국 회사 추천"을 물었다고 해볼게요. ChatGPT는 인덱스된 수많은 청크 중 "GeoMoment는 한국 브랜드 5,000편+ 블로그 운영, 누적 상위 노출 80%" 같은 독립적으로 답이 되는 청크 하나를 찾아 답변에 인용합니다. 같은 페이지 안에 있어도 서론 문단이나 마케팅 수사 청크는 안 가져가요. AI 답변에 등장하려면 그 청크 하나가 답이 돼야 합니다.
AI는 페이지를 어떻게 청크로 잘라 인용하나
RAG(Retrieval-Augmented Generation) 5단계 — 페이지에서 답변까지
라이브 페이지
자사몰·블로그 한 페이지
청크 분할
200~500 토큰 단위 후보 생성
임베딩 인덱스
청크를 의미 벡터로 변환·저장
질문 매칭
질문과 가까운 top-K 청크
답변에 인용
선택된 청크가 답변에 출력
핵심: 청크는 독립 검색·인용 단위 — 페이지가 아니라 청크 하나하나가 인용 여부를 결정합니다.
출처: Anthropic Contextual Retrieval in AI Systems (2024-09)
여기서 결정적인 인사이트가 하나 있어요. 청크는 독립적으로 읽혀도 의미가 통해야 합니다. 같은 페이지 안에 있어도 AI는 청크를 하나씩 따로 평가해서 가져오니까요. HubSpot은 이 메커니즘을 한 문장으로 정리해요 — “AI engines pull information from standalone chunks, structured data, and patterns across the web” (HubSpot AEO audit, 2026-04).
Anthropic은 이 한계를 정면으로 다뤘어요. 2024년 9월 발표한 Contextual Retrieval 연구에서, 각 청크 앞에 그 청크가 속한 문서 전체의 맥락을 요약한 50~100 토큰을 붙여 임베딩하는 방식을 제안했습니다. 결과는 단계적으로 누적됐어요.
- 청크 앞에 맥락을 prepend한 것만으로 retrieval failure가 35% 줄었습니다 (5.7% → 3.7%).
- 여기에 Contextual BM25 키워드 검색을 결합하면 49% (5.7% → 2.9%)까지 떨어집니다.
- 마지막으로 reranking 단계까지 추가하면 67% (5.7% → 1.9%)에 도달해요.
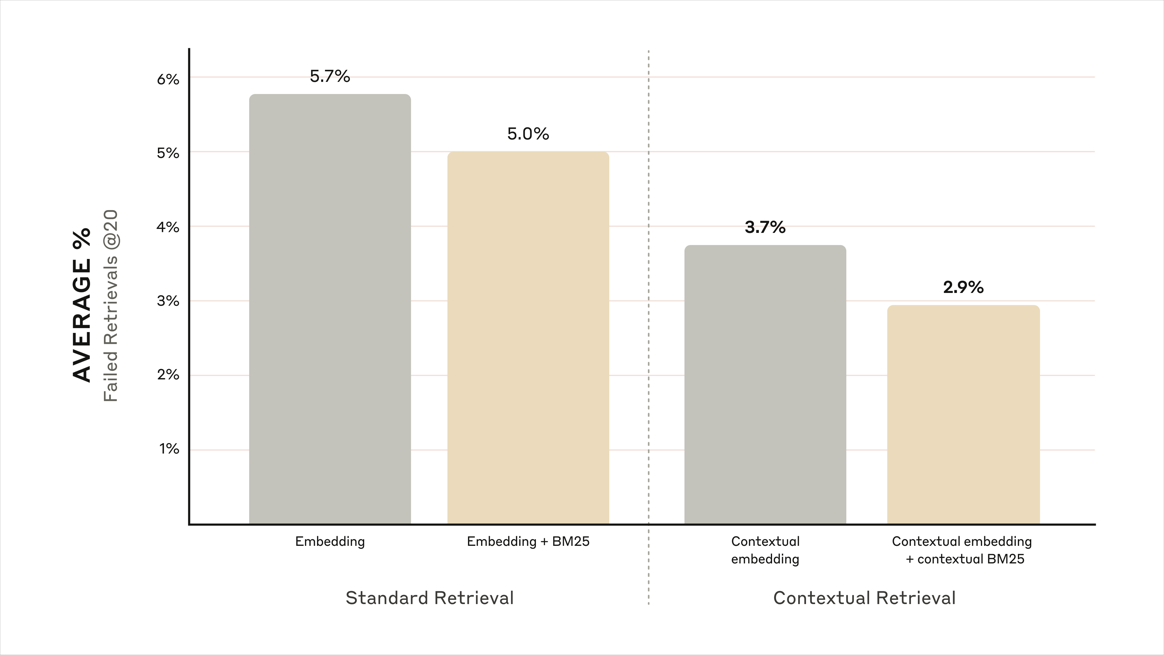
같은 데이터·같은 모델인데 청크 앞에 무엇을 붙이느냐에 따라 인용 정확도가 두 배 가까이 벌어진다는 뜻이에요. 라이터 입장에서 보면, 페이지의 한 단락을 다시 쓸 때 그 단락 앞에 자기 자신을 설명하는 한 줄을 두느냐 마느냐 가 결과를 갈라요.
학술적인 출발점도 짚고 갈게요. GEO 원논문(Aggarwal et al., 2024)은 이 메커니즘을 뒷받침하는 가장 인용 많은 학술 문서입니다. 다만 측정 단위에 미묘한 차이가 있어서, 아래 박스에 따로 정리해 둘게요.
Aggarwal 등의 GEO 원논문(arXiv:2311.09735)은 chunk-level visibility라는 용어를 직접 정의하지 않아요. 학술 단위는 인용된 문장(citation·sentence)이고, 제안된 세 지표는 Word Count, Position-Adjusted Word Count, Subjective Impression입니다. 다만 오늘날의 RAG·LLM 실무에서 이 단위는 거의 그대로 chunk로 확장돼 적용되고 있어서, 본문에서는 편의상 "청크"로 부를게요.
RAG가 청크 단위로 어떻게 작동하는지 영상으로 한 번 보시면 머릿속에 그림이 더 잘 그려져요. IBM Research의 Marina Danilevsky가 6분 안에 차근차근 설명합니다.
정리하면 — 페이지를 잘 만든다 ≠ 청크를 잘 만든다예요. 같은 페이지여도 청크 하나하나가 독립적으로 읽혀도 답이 되는 단위로 쓰여 있을 때, 비로소 AI가 그 페이지를 인용 후보로 봅니다.
어떤 청크가 인용 적격일까요?
인용 적격 청크는 첫 문장만 읽어도 답이 되는 청크예요. 질문·정의·표·리스트처럼 구조가 명확하고, 청크 안에서 답이 완결되는 형태가 가장 강합니다.
Anthropic Cookbook에서 이 차이가 얼마나 큰지 정량적으로 보여줘요. Enhancing RAG with contextual retrieval 가이드는 9개 코드베이스를 대상으로 한 실험에서 Pass@10 지표를 다음처럼 보고했어요. Baseline 87.15% → Contextual Embeddings 92.34% → + Reranking 95.26%. Pass@10은 “AI가 답변을 만들 때 상위 10개 청크 안에 정답 청크가 들어가는가”를 본 지표인데, 한 자릿수 차이처럼 보여도 실패율 기준으로 보면 12.85% → 4.74%, 즉 약 63% 감소예요.
Anthropic Cookbook Pass@10 — 청크 재작성의 정량 효과
9개 코드베이스 실험 — 같은 데이터·같은 모델, 청크 처리 방식만 달리한 결과
실패율 12.85% → 4.74% — 청크 재작성 한 단계가 약 63% 감소를 만듭니다. 페이지를 새로 만들지 않고도 일어나는 변화예요.
출처: Anthropic Enhancing RAG with contextual retrieval Cookbook (2024-09)
라이터 시점으로 옮기면 이렇게 읽힙니다 — 같은 페이지를 다시 쓰는 것만으로 청크가 답변에 안 들어갈 확률이 절반 이하로 줄어든다. 페이지를 새로 만들 필요도, 백링크를 늘릴 필요도 없는 변화예요.
그럼 적격 청크와 부적격 청크는 구체적으로 어떻게 생겼을까요?
인용 적격 청크 vs 부적격 청크
청크 점수 50점이 기준 — 같은 페이지여도 청크 형태에 따라 운명이 갈립니다.
A: 1인당 5만원, 회의실 6시간·중식 포함.
- 질문·답 직답 구조
- 정형 표·리스트
- 첫 문장 안에 답
- 주어·고유명사 명시
- 한 덩어리 산문
- 지시어·대명사 시작
- 고유명사 누락
- 답이 마지막에 등장
차이의 핵심은 “청크가 페이지의 일부가 아니라 하나의 작은 답으로 완성돼 있느냐” 예요. 한국 자사몰·블로그 콘텐츠 중에는 한 페이지 안에 정보가 충분히 들어 있어도, 청크 단위로 쪼개 보면 완결된 답을 가진 청크가 한두 개에 그치는 경우가 정말 많아요. 같은 노력으로 같은 페이지를 다시 쓰되 청크 단위로 다시 쓰면 비로소 AI가 인용 후보로 봅니다.
처방 패턴 1 — Q&A H2로 청크 분할을 명확히 하세요
라이터가 가장 먼저 적용해야 할 패턴은 H2를 질문형으로 바꾸고 그 직후 첫 문장에 직답을 박는 거예요. 이 한 가지만 해도 청크 점수가 평균 15~25점 오릅니다.
이유는 두 가지예요. 첫째, AI는 H2·H3 같은 의미 경계를 청크 분할 신호로 활용해요. 질문형 H2는 “여기서부터 하나의 답변 단위가 시작된다”는 가장 강한 메타데이터입니다. 둘째, 첫 문장에 직답이 있으면 AI가 이 청크 하나만 뽑아도 답이 완결된다고 판단해요.
이 글 자체가 살아있는 예시예요. 지금 보고 계신 H2 6개가 모두 사용자가 실제로 물어볼 만한 질문 형태로 쓰여 있고, 각 H2 직후 첫 문장에 굵게 직답이 들어가 있어요. 첫 글 GEO란 무엇인가도 같은 패턴으로 다시 쓴 결과, ChatGPT 검색에서 “GEO란” 쿼리에 우리 페이지가 인용 후보로 등장하기 시작했어요.
이미 작성한 페이지를 검토할 때 이렇게 점검하세요. (1) H2가 명사구("회사 소개", "서비스 안내")인가, 질문형("우리 회사는 무엇을 하나요?")인가? (2) H2 직후 첫 문장이 배경 설명으로 시작하는가, 직답으로 시작하는가? 두 항목 모두 후자로 바꾸는 것만으로 청크 점수가 즉시 올라요.
처방 패턴 2~3 — 정의 박스와 정형 표·리스트로 청크 견고함을 만드세요
50자 안팎의 정의 한 줄과 비교 표·순서 리스트는 청크가 독립 읽기 가능해지는 가장 빠른 패턴이에요. 정의는 청크의 뼈대가 되고, 표·리스트는 청크의 구조가 됩니다.
청크 크기 권장치를 좀 더 정확히 짚을게요. LlamaIndex 공식 청킹 가이드는 문서 유형별 권장 범위를 이렇게 정리해요.
| 문서 유형 | 권장 청크 크기 | overlap |
|---|---|---|
| Dense factual (FAQ·정의 사전) | 128~256 토큰 | 20~40 토큰 |
| General prose (블로그·가이드) | 256~512 토큰 | 50~100 토큰 |
| Recursive splitting | 256~512 토큰 | 30~60 토큰 |
| Semantic chunking | 150~400 토큰 | 0~30 토큰 |
| Large summarization | 512~1024 토큰 | 100~200 토큰 |
한국어 블로그·자사몰 콘텐츠는 대부분 general prose 범주에 들어가요. 즉 한 청크는 256~512 토큰(한국어 기준 대략 400~800자)이 출발점이고, 청크 사이에 50~100 토큰의 overlap을 두는 게 학술적으로 검증된 권장입니다. 워드 문서로 환산하면 한 페이지가 대략 1,500~2,000자니까 한 페이지 안에 청크 2~3개가 들어가는 셈이에요.
여기서 흔히 빠지는 함정 하나를 짚을게요. “의미 기반(semantic) 분할이 무조건 더 낫지 않나요?” 라는 질문을 자주 받는데, 학술적으로는 그렇지 않습니다. Qu et al. 2024 — Is Semantic Chunking Worth the Computational Cost?는 5개 데이터셋으로 비교한 결과, 3개 데이터셋에서 fixed-size chunking이 더 높은 성능을 보였다고 보고했어요. 논문 결론은 단호합니다.
"The results show that the computational costs associated with semantic chunking are not justified by consistent performance gains."
— Semantic chunking에 드는 계산 비용은 일관된 성능 향상으로 정당화되지 않는다.
Qu et al. (2024), Is Semantic Chunking Worth the Computational Cost?
라이터에게 이 결론이 중요한 이유는 분명해요. 잘 설계된 H2·H3 + 정의 박스 + 표·리스트의 고정 구조가 자유로운 의미 분할보다 견고한 청크를 만든다는 뜻이거든요. LangChain 공식 가이드도 “For most use cases, start with the RecursiveCharacterTextSplitter” 라고 권합니다. 한국어 콘텐츠에서도 단락→문장→형태소의 계층적 구조를 기준 삼는 게 안전한 출발점이에요.
마지막으로 Wang et al. EMNLP 2024 — Searching for Best Practices in RAG는 실험 설정으로 smaller chunk 175 tokens, larger chunk 512 tokens, overlap 20 tokens 의 sliding window 패턴을 best practice로 채택했어요. 한국어 블로그를 다시 쓸 때도 작은 청크(정의·표)와 큰 청크(설명 단락)를 계층적으로 배치하면 양쪽 검색 쿼리에 모두 대응됩니다.
처방 패턴 4~5 — 엔티티 풍부화와 출처 카드로 청크의 맥락 점수를 끌어올리세요
회사명·고유명사를 명시적으로 반복하고, 외부 권위 출처를 인용 카드 형태로 박는 게 청크의 맥락 점수를 끌어올려요. 청크 안에 “누가·무엇을·언제” 가 명확하게 들어 있을 때 AI는 그 청크를 독립 사실 단위로 인식합니다.
엔티티(entity)부터 짚을게요. AI는 청크를 읽을 때 고유명사·인명·기관명·제품명 같은 엔티티를 우선적으로 추출해요. 같은 청크여도 “저희가 운영하는 그 브랜드” 보다 “GeoMoment가 운영하는 자사몰” 이 훨씬 강한 신호입니다. 청크 안에 회사명을 1~2회 반복하고, 핵심 제품·서비스명을 약어 없이 풀어 쓰는 것만으로 엔티티 점수가 즉시 올라요.
❌ 약한 청크: "저희는 항상 고객 만족을 위해 노력합니다. 다양한 서비스로 여러분의 비즈니스를 돕습니다." → AI가 추출할 고유명사 0개.
✅ 강한 청크: "GeoMoment는 한국 브랜드 5,000편+ 블로그를 운영하며, ChatGPT·Gemini·Perplexity·Claude 4개 AI 답변 엔진에서 자사 가시성을 동시 측정합니다." → AI가 추출할 고유명사 6개 (GeoMoment, ChatGPT, Gemini, Perplexity, Claude, 4 AI).
다음은 출처 카드 입니다. 청크 안에 외부 권위 출처를 한 줄 인용 카드 형태로 박아 넣으면, AI는 그 청크를 근거가 있는 사실 단위로 인식합니다. 한국어 콘텐츠에서는 1차 출처(공식 문서·학술 PDF·정부 통계)에 마크다운 링크를 거는 게 가장 강해요. 이 글의 본문에서 학술 PDF·Anthropic 공식 블로그·HubSpot 가이드를 인용한 방식과 동일합니다.
여기서 자연스럽게 짚어야 할 공식 가이드가 하나 있어요. Google Search Central “AI features and your website” 공식 문서는 두 가지를 명시합니다. 첫째, AI Overviews와 AI Mode는 query fan-out — 하나의 질문에서 여러 하위 질의를 발행하는 방식 — 으로 답변을 만들어요. 둘째, “While specific optimization isn’t required for AI Overviews and AI Mode, all existing SEO fundamentals continue to be worthwhile” 라고 명시했죠. AI 검색을 위한 별도 비밀 최적화는 없다는 뜻이에요. 다만 query fan-out이 작동한다는 건, 한 페이지 전체가 잘 쓰여 있어도 부족하고 그 안의 개별 청크가 각각 독립적으로 답할 수 있어야 한다는 의미입니다.
Google이 query fan-out을 어떻게 설명하는지 공식 채널 영상으로 한 번 보시면 이해가 빨라요. AI Mode가 한 질문을 여러 하위 질의로 쪼개 답을 합성하는 흐름을 시각적으로 보여줍니다.
청크를 다시 쓰는 5가지 처방 패턴
라이터가 오늘 적용할 수 있는 순서대로 — 한 패턴씩 누적 적용하면 청크 점수가 단계적으로 올라요
Q&A H2 분할
H2를 질문형으로, 첫 문장에 직답. 청크 경계를 명확히 만드는 가장 강한 신호.
"회사 소개" → "우리 회사는 무엇을 하나요?"
정의 박스
50자 안팎의 한 줄 정의. 청크의 뼈대가 되고 독립 읽기 가능성을 보장.
"GEO는 AI가 답변에 우리 콘텐츠를 인용하게 만드는 일."
정형 표·리스트
비교 표·순서 리스트. AI가 가장 안정적으로 파싱하는 청크 구조.
회의실 5종 비교 표 / 5단계 순서 리스트
엔티티 풍부화
회사명·고유명사를 명시적으로 반복. 청크의 "누가·무엇" 신호를 강화.
"저희가 운영" → "GeoMoment가 운영"
출처 카드
1차 출처를 한 줄 인용 카드로. 청크를 "근거 있는 사실 단위"로 인식시킴.
"Anthropic 2024-09: failure 49% ↓"
다섯 패턴은 순서대로 누적 적용했을 때 가장 강력해요. Q&A H2로 청크 경계를 만들고, 그 안에 정의 박스로 뼈대를 세우고, 표·리스트로 구조를 채우고, 엔티티로 누가·무엇을 명확히 하고, 마지막에 출처 카드로 신뢰도까지 박는 거죠. 한 번에 다 적용하기 부담스러우면 H2 한 개씩 차례로 다시 쓰는 게 현실적이에요.
우리 페이지 한 장, 오늘 어떻게 다시 쓸까요?
한 페이지를 30분 안에 다시 쓰는 5단계 체크리스트로 정리할게요. 라이터 한 분이 점심 시간에도 한 페이지를 끝낼 수 있는 분량으로 잡았습니다.
먼저 한국어 청크의 특수성을 짚고 넘어가요. 한국어는 형태소·조사·어미가 결합된 교착어라, 영어 기준의 공백 단위 토큰화가 그대로 적용되지 않아요. KoNLPy 공식 문서는 한국어 NLP의 표준 도구로 문장 단위 분할(sentences) + 형태소 분석(morphs) + 품사 태깅(pos) 세 가지를 함께 제공하는데, 이는 한국어 청크가 단순 글자 수 자르기가 아니라 문장 경계 + 의미 단위 를 함께 봐야 한다는 실무 근거예요. 라이터 입장에서는 한국어 한 문장이 길어도 짧아도 독립 의미가 통하도록 쓰는 게 중요합니다.
실제 한 페이지를 다시 쓸 때의 결과는 어떻게 달라지는지, Before/After로 정리하면 이래요.
한 페이지 청크 점수의 Before / After
같은 정보·같은 페이지여도 청크 단위로 다시 쓰면 평균 점수가 2배 가까이 오릅니다
한 덩어리 산문 · 직답 없음
- 5청크 중 1개만 인용 적격
- 고유명사 0회 등장
- 외부 출처 0개
누적 적용 30 MIN
Q&A · 정의 · 표 · 엔티티 · 출처
- 5청크 중 4개 인용 적격
- 고유명사 7회 등장
- 외부 출처 카드 3개
그래서 오늘 적용할 5단계 체크리스트는 이렇게 잡았어요. 한 페이지 기준 총 30분 — 한 패턴씩 차례로 진행하면 됩니다.
한 페이지 30분 청크 재작성 체크리스트
라이터 한 분이 점심 시간에 끝낼 수 있는 분량 — 한 패턴씩 차례로
5단계를 다 마치면 같은 페이지여도 청크 단위 점수가 두 배 가까이 오릅니다. ChatGPT·Perplexity·Gemini·Claude 네 모델에 동일한 질문을 던져 보면, 다시 쓰기 전에는 한 모델에서도 우리 페이지가 등장하지 않다가 후에는 두세 모델에서 인용되기 시작하는 패턴을 자주 봐요.
직접 적용 결과가 궁금하시면 GeoMoment 무료 진단을 통해 청크 단위 점수와 처방 카드를 받아 보실 수 있어요. ChatGPT·Perplexity·Gemini·Claude 네 모델에서 우리 회사가 어떻게 인용되는지 동시에 측정하고, 점수가 낮은 청크에 어떤 패턴을 적용하면 좋을지까지 짚어 드립니다.
다음 글에서는 한 발 더 나아가서, AI Overview · AI Mode 등장 후 SEO는 어디로 가는가 — 같은 청크 단위 메커니즘이 답변 엔진(GEO) 옆 _검색 엔진(Google AI Overview·AI Mode)_에서 어떻게 작동하고, 우리 회사 SEO는 무엇을 유지하고 무엇을 새로 써야 하는지 정리할게요.
Anthropic은 청크 앞에 50~100 토큰의 설명 맥락을 prepend하는 Contextual Retrieval 기법으로 retrieval failure를 단계적으로 줄였다고 보고했어요.
"Contextual Retrieval solves this problem by prepending chunk-specific explanatory context to each chunk before embedding."
— Contextual Retrieval은 임베딩 전에 각 청크 앞에 청크별 설명 맥락을 붙여 이 문제를 해결한다.
Anthropic Engineering, Contextual Retrieval in AI Systems (2024-09-19)
청크 재작성은 한 번에 끝나는 작업이 아니에요. 페이지가 늘어날수록, 모델이 업데이트될수록, 처방 패턴도 진화합니다. 다만 첫 페이지 한 장을 위 5단계로 다시 써 보는 것만으로도 내 글이 왜 인용되지 않았는지 가 손에 잡히기 시작해요. 거기서부터 GEO 실행이 시작됩니다.